Автор: Евгений Зубарев, консультант департамента «Индустрия X» компании Axenix
Практически во всех крупных промышленных предприятиях принято внимательно следить за работой оборудования. И отслеживать ее удобно с помощью двух простых показателей – доступность оборудования и эффективность его использования. Существуют различные определения, подходы к расчету этих показателей. В рамках данной статьи мы будем использовать упрощенные понятия.
Доступным называется оборудование, которое может выпускать продукцию и использоваться в технологическом процессе. В свою очередь, время на техническое обслуживание и ремонт снижают показатели доступности оборудования. На российских предприятиях применяется показатель КТГ – коэффициент технической готовности. Он позволяет понять, какое оборудование мы можем задействовать в технологическом процессе. Как правило, обеспечение высоких показателей КТГ является задачей службы ТОиР.
Но недостаточно просто обеспечить высокий КТГ. Доступное оборудование необходимо эффективно использовать для выполнения производственных задач, оно не должно простаивать без дела. Для учета эффективности использования оборудования и применяется показатель КИО – коэффициент использования оборудования. Он, в свою очередь, показывает, насколько эффективно производственные службы используют доступное оборудование.
Работа с двумя этими базовыми показателями позволяет раскрыть существенные резервы в области операционной эффективности во многих компаниях, поэтому многие руководители производственных компаний ответственно подходят к сбору данных для расчета этих показателей, внимательно отслеживают отклонения и выполняют регулярный мониторинг этих показателей.
На практике рассчитать эти базовые показатели оказывается совсем непросто, потому что данные для расчета КИО и КТГ находятся в различных системах, хранятся с разной аналитикой и дискретностью.
Прежде чем перейти к задаче расчета КИО и КТГ, стоит сделать шаг назад и посмотреть на архитектуру предприятия в целом, потому что отдельные компоненты данных для расчета КИО и КТГ хранятся в разных системах и на разных уровнях.
В работе крупных промышленных предприятий задействованы десятки бизнес-процессов и технологических операций. Каждый из них – источники данных, которые сегодня, при помощи различных систем, используются для решения множества задач, от планирования и менеджмента на уровне организации до организации производственного процесса. И все это многообразие данных, равно как и информационные системы, которые их используют, должны быть систематизированы на уровне ИТ-архитектуры. В противном случае цифровая основа предприятия просто не сможет существовать и работать.
Для систематизации могут быть использованы различные стандарты, например международный ISA-95, который выделяет 5 уровней иерархии. В упрощенном виде уровни иерархии можно представить следующим образом.
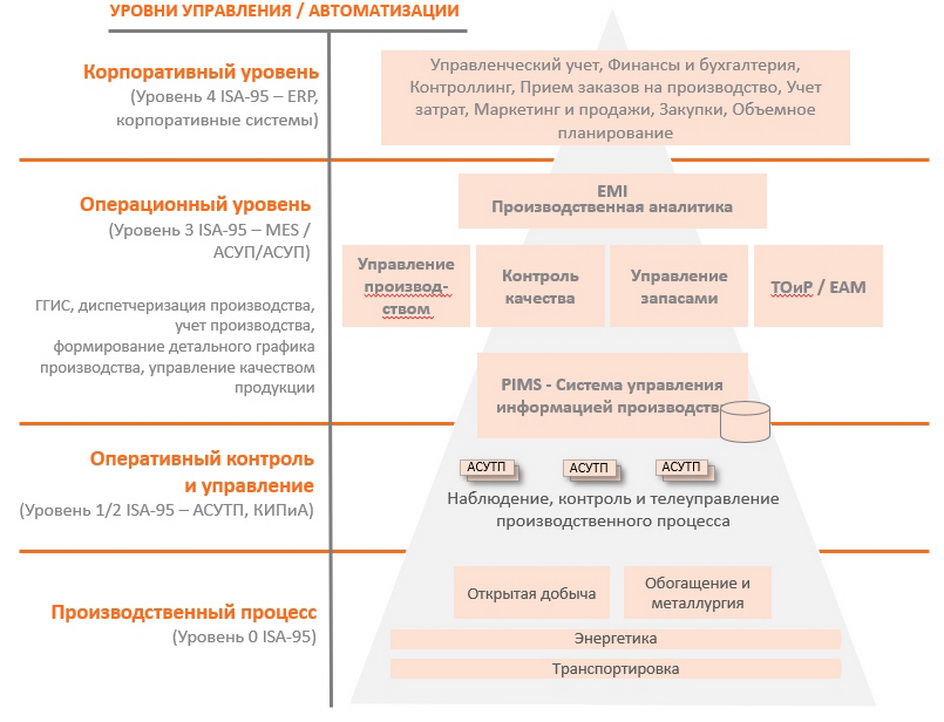
Согласно стандарту, данные в информационном пространстве предприятия последовательно перемещаются между его разными уровнями. Их собирают контрольно-измерительные приборы (уровень 1), полученные данные обрабатываются в системах контроля, а также используются для мониторинга и оперативного управления технологическим процессом (уровень 2). Затем данные передаются на третий уровень, в MES (Manufacturing Execution System), систему управления производственными процессами, где выполняется учет производственных операций на детальном уровне (операции по агрегатам и единицам продукции). Агрегированные в MES данные поступают на следующий, четвертый уровень, в ERP-систему, которая используется для планирования и распределения ресурсов предприятия.
Применительно к КИО и КТГ в качестве источников данных выступают данные о работе оборудования с уровня АСУ ТП, а также дополнительная информация с уровня MES. Расчет КИО и КТГ выполняется на уровне MES, а в некоторых случаях и на уровне ERP. Поэтому задача расчета КИО и КТГ требует синхронизации работы множества систем, расположенных на разных уровнях архитектуры предприятия.
На каждом из перечисленных уровней для принятия управленческих решений требуется разная степень детализации информации. Кроме того, в разных подразделениях используются различные информационные системы и различные виды отчетности. При этом сотрудники какого-то подразделения могут внести изменения в данные в ручном режиме, не изменив их в системе-источнике. Не исключаются ошибки в справочных данных, ошибки синхронизации систем, различаться может глубина синхронизации между различными информационными системами.
Все это – причины расхождения данных, которые могут привести к искажению информации в верхнеуровневых системах, возникновению ошибок в отчетности и аналитике и, в конечном счете, к принятию ошибочных решений на уровне менеджмента как отдельных процессов, так и предприятия в целом. Дифференциация данных приводит к тому, что специалисты по-разному оценивают информацию о состоянии производственных процессов и принимают решения, которые конфликтуют с теми, что принимаются на уровне других подразделений. Результатами такого явления могут стать появление в компании неофициального процесса получения данных, трудозатраты на «ручную» перепроверку информации, падение эффективности и обесценивание функциональности действующих информационных систем, а следовательно и инвестиций в их создание и развитие.
В качестве примера могу привести опыт одного из наших заказчиков, крупной горнодобывающей компании. Здесь в различных системах фигурировали разные данные по статусам работы оборудования. В результате возникали расхождения в расчетах важнейших для предприятия коэффициентов использования оборудования (КИО) и технической готовности (КТГ).
Эта проблема была видна специалистам разных департаментов предприятия, и они обращались за данными к тем системам, показатели которых считали корректными. В результате у каждого из них появился собственный неофициальный регламент получения информации, которая часто отличалась о той, которой оперировали другие подразделения. И это было причиной недопонимания и разногласий между производственными и ремонтными службами.
Аудит, который мы провели, выявил множество причин такого расхождения данных:
Расхождения данных, обусловленные этими причинами, могут отличаться в зависимости и от самой причины, и от временного диапазона. Вот какими они были в течение одного квартала.
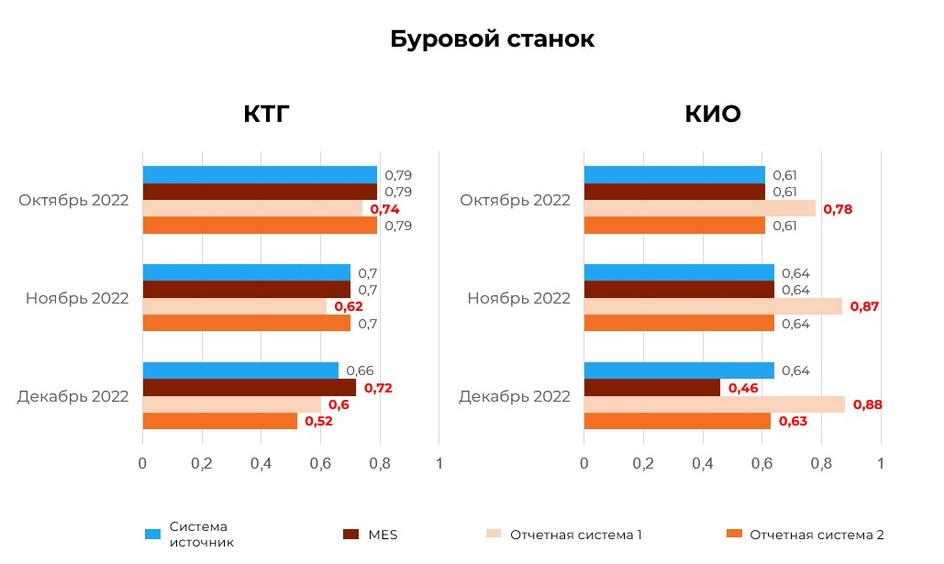
Обратите внимание на данные КТГ за декабрь. Разброс в них весьма заметен по сравнению с показателями за октябрь. Но даже незначительное, в 0,05 расхожде6ние может стать причиной управленческих решений, стоимость которых будет достигать в масштабах предприятия сотен тысяч рублей.
Этот пример со статусами работы оборудования (КИО и КТГ) – только один из множества возможных. Могут отличаться такие важные показатели, как объёмы поступившего сырья и произведенной продукции для каждого технологического процесса, данные по сотрудникам, данные по доступным материалам и запасным частям, остатки на складах, план-факт анализ, учет простоев и наработок, регистрация нарушений, учет показателей качества.
Выявление и устранение расхождений в данных – не самая простая, но решаемая задача. Эту работу можно разделить на три основных этапа. На первом этапе необходимо определить перечень информационных систем, проанализировать схему потоков данных между ними и определить перечень показателей, расхождения по которым необходимо установить. Одновременно необходимо определить и временной интервал для анализа причин расхождений на исторических данных.
Второй этап – сравнить справочные данные систем, убедиться, что они идентичны. Если справочные данные различаются, то необходимо выбрать показатели, которые используют идентичную справочную информацию во всех системах. В дальнейшем ИТ-системы должны иметь один источник справочной информации для исключения расхождений и удобства поддержания актуальной информации
Наконец, необходимо сравнить значения информационных систем по показателям, зафиксировать разночтения и определить их причины.
Важно не только выявить и устранить расхождения в данных. Предприятию с развитым ИТ-ландшафтом информационных систем необходимо еще и предотвратить их. И для этого можно порекомендовать несколько важных мер.
Прежде всего, необходимо разработать и утвердить методику работы с данными, при этом учесть операции при добавлении, удалении, корректировке данных, а также утвердить возможную глубину изменения данных и периодичность обновления.
Кроме того, необходимо разработать методику ведения нормативно справочной информации. Например, в случае добавления новых единиц учета, таких как оборудование или показатели, сделать это во всех необходимых системах синхронно, при этом должна быть определена мастер-система, в которую вносятся изменения, а изменения в других системах происходят автоматически или вручную по установленному регламенту.
Также следует провести аудит. Он потребуется, чтобы убедиться в корректности данных, собираемых всеми системами, оценить соответствие принятым методикам и регламентам. Если во время аудита будет выявлено, что какой-то из процессов работы с данными не соответствует стандартам или не «покрывается» информационными системами, то необходимо разработать мероприятия по устранению отклонений, определить критичность задачи и включить в дорожную карту развития.
Наконец, основываясь на разработанных методиках и учитывая результаты аудита, следует настроить передачу данных из систем-источников на уровень MES и далее на уровень ERP. При этом необходимо минимизировать ручной ввод данных и везде, где это возможно, запретить ручные корректировки одних и тех же данных на разных уровнях и в разных системах. Для ручного ввода данных предстоит разработать отдельную методику.
Предотвратить расхождение в данных, их недостоверность в информационных системах и, как следствие, принятие ошибочных управленческих решений, поможет создание «единого хранилища правды» – массива данных, корректность которых базируется на единых правилах их сбора, ввода в различные системы, закрепленных в методиках и регламентах. В противном случае ошибки могут возникнуть на любом этапе использования главного актива современного предприятия.
Реклама. ООО “Информационно-Аналитический Центр”. https://itrend.ru/












